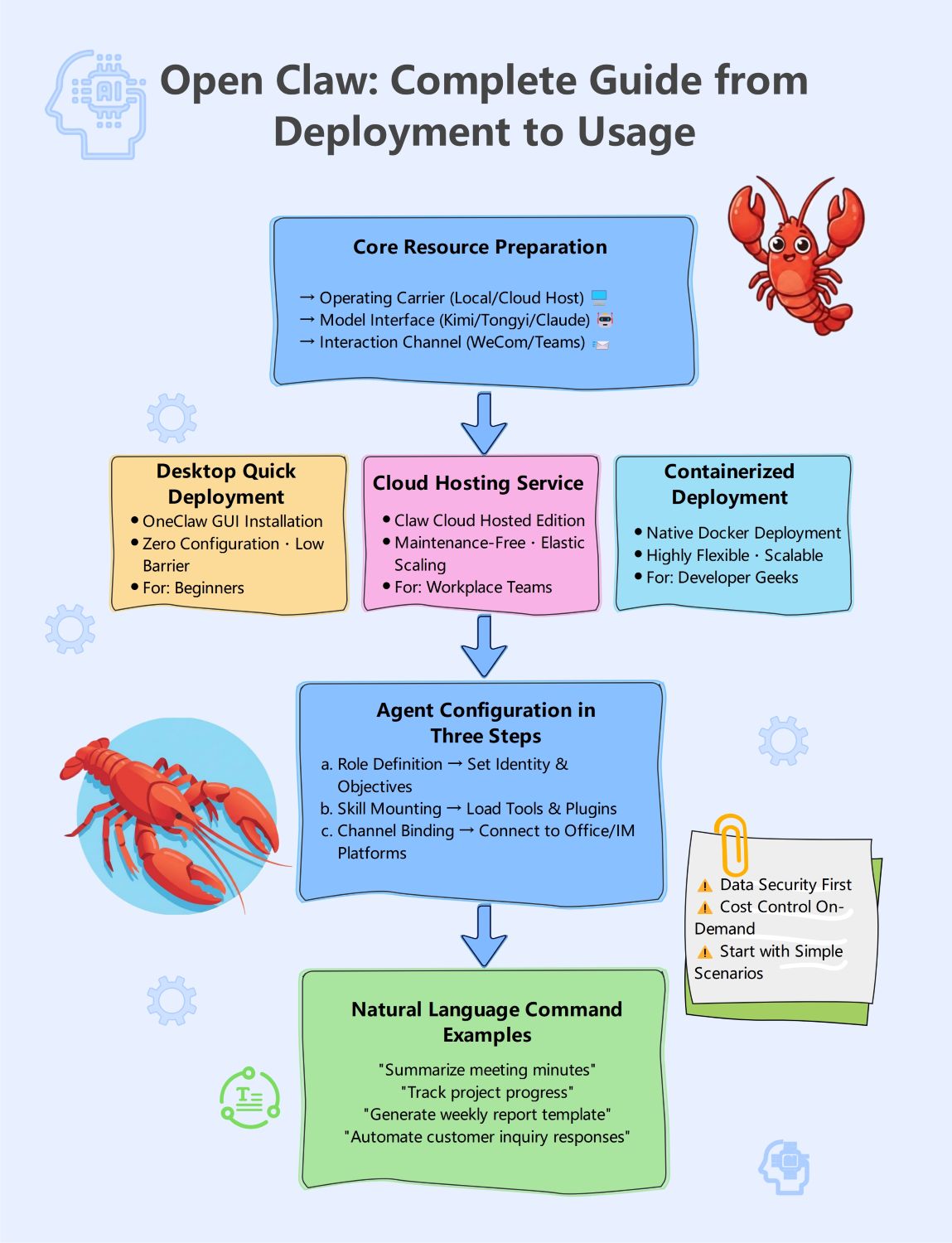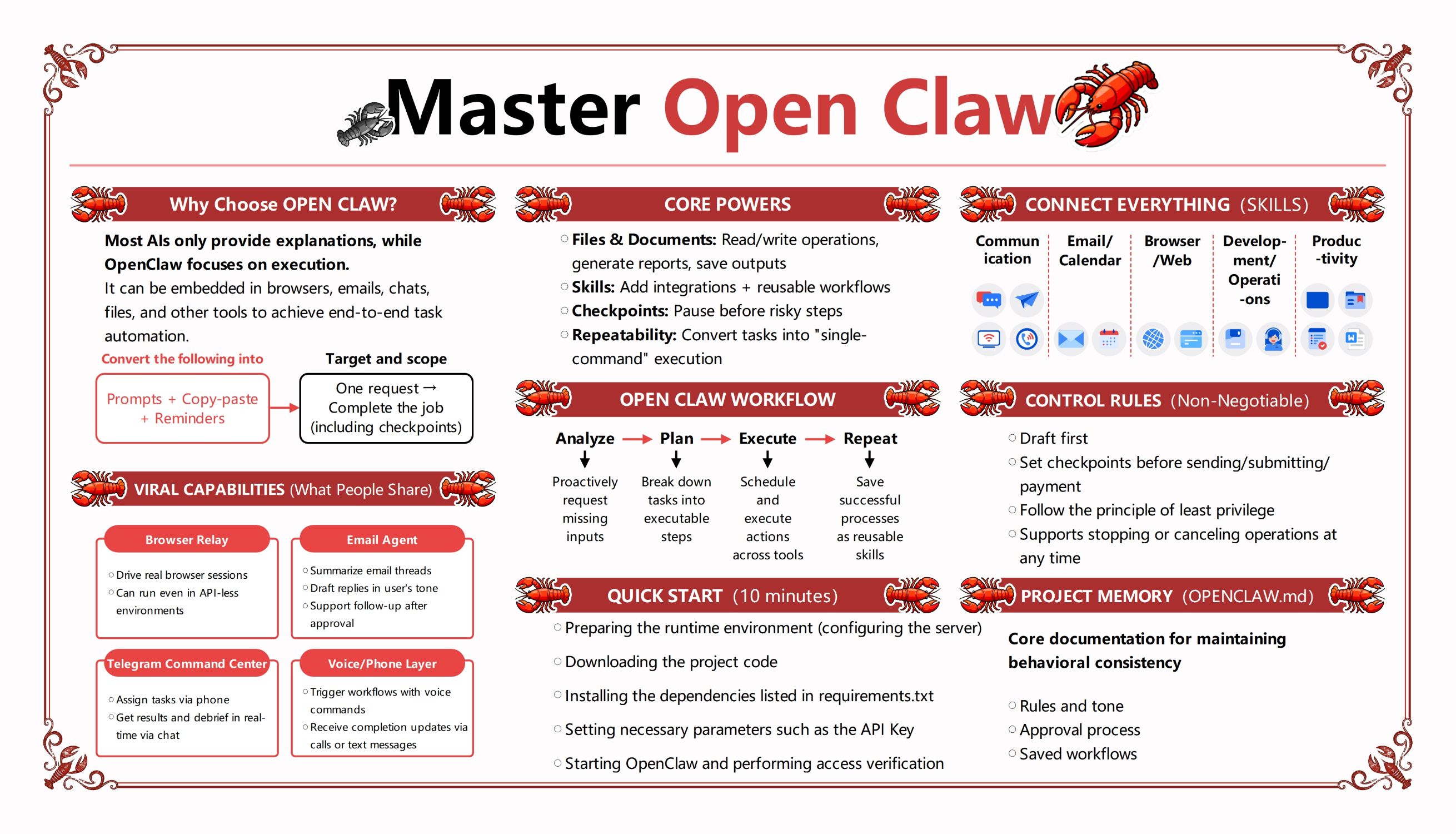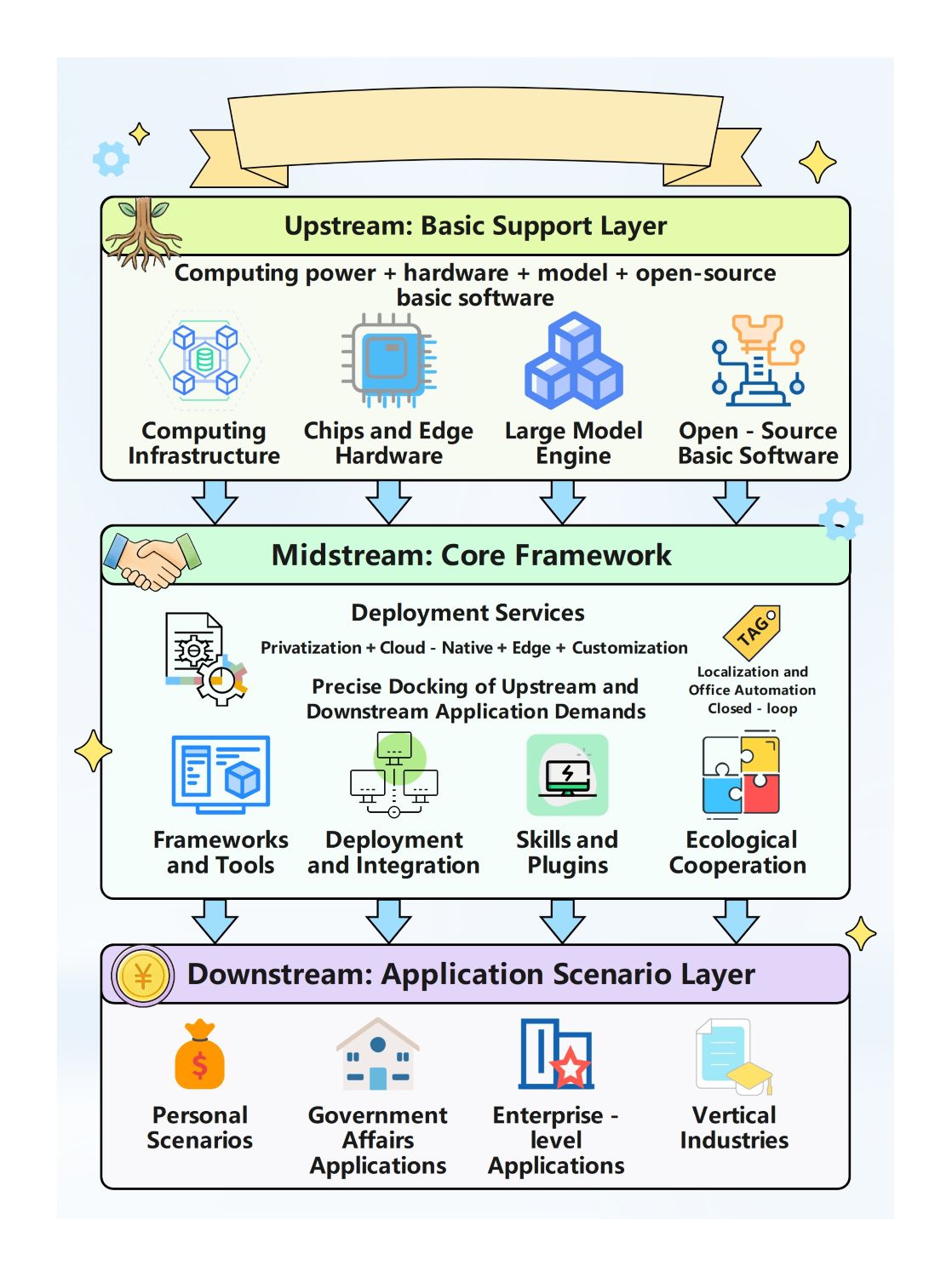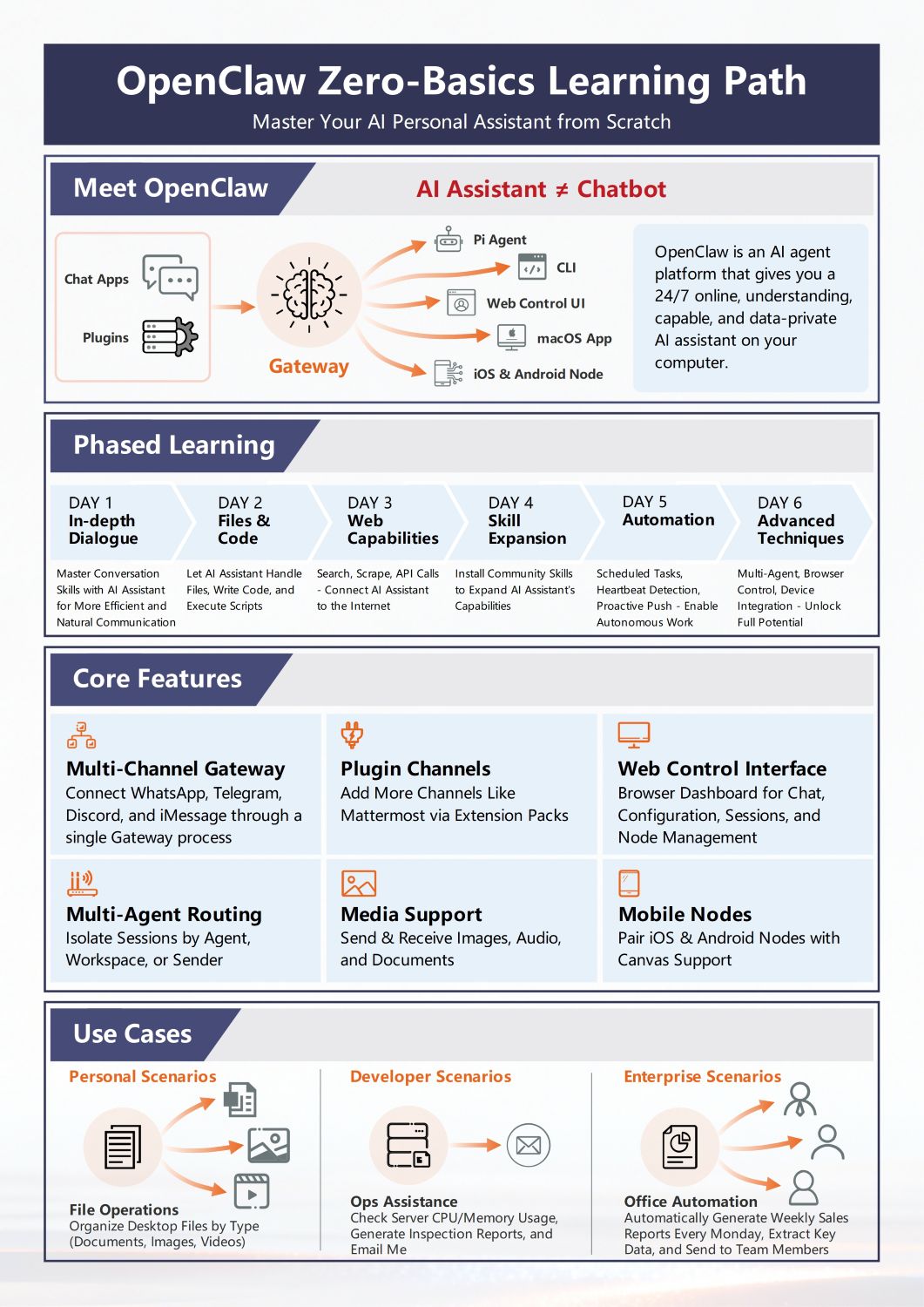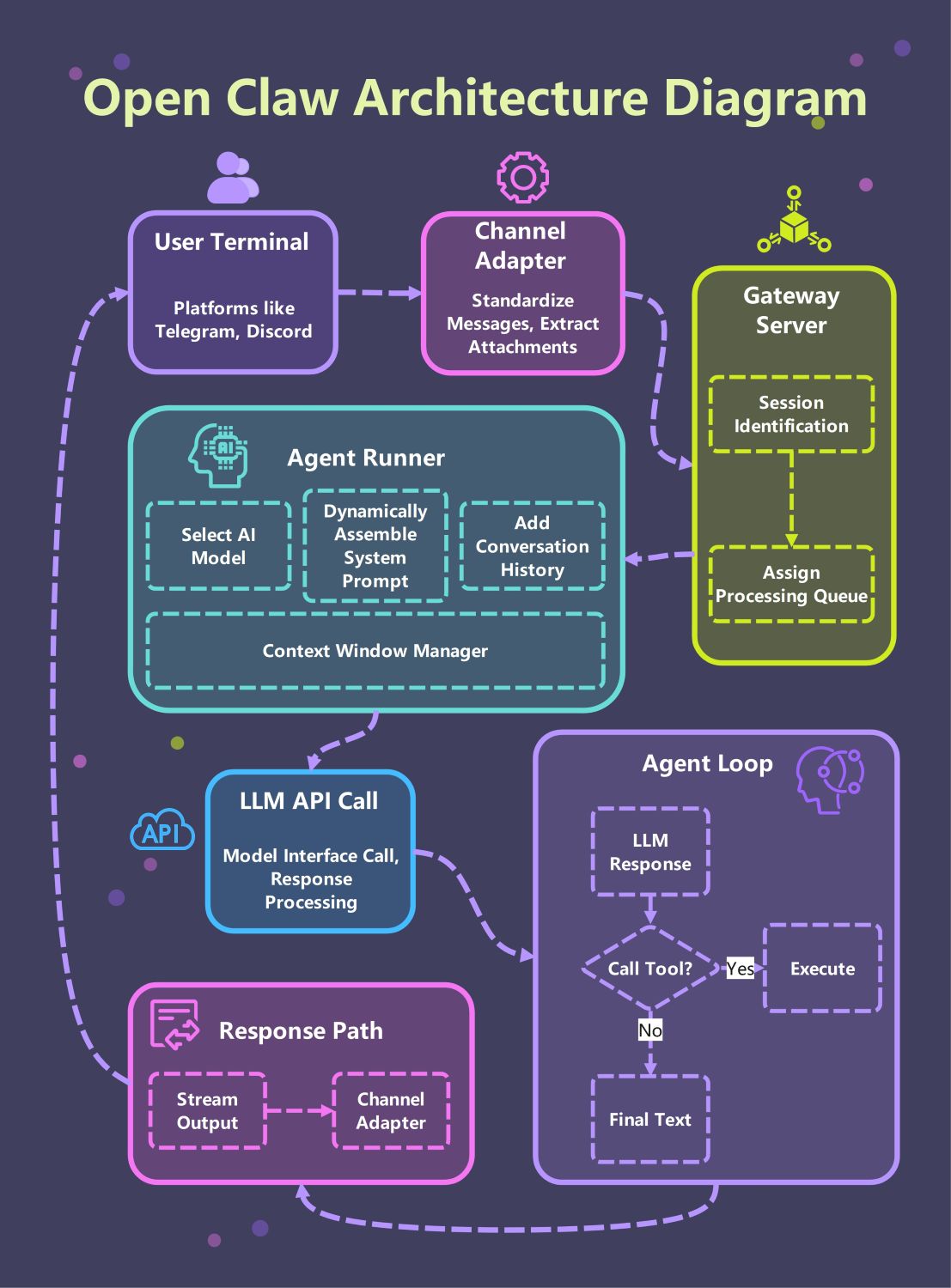
Sobre este Diagrama de Arquitetura Open Claw
Este template fornece um guia visual abrangente do sistema Open Claw. Ele destaca o caminho crítico desde os terminais do usuário através do gateway até o ciclo principal do agente, facilitando a compreensão de como os componentes modulares de IA interagem em um ambiente profissional.
Terminal do Usuário e Adaptador de Canal
O sistema começa no terminal do usuário, onde as pessoas interagem através de plataformas como Telegram ou Discord. O adaptador de canal então padroniza essas mensagens recebidas e extrai quaisquer anexos relevantes para processamento posterior.
- Integração com Telegram e Discord
- Padronização de mensagens
- Extração de anexos
- Suporte multiplataforma
Camada de Servidor Gateway
O servidor gateway atua como o controlador principal de tráfego para toda a arquitetura. Ele realiza identificação de sessão para manter o estado do usuário e atribui solicitações a filas de processamento para garantir um desempenho equilibrado e suave.
- Identificação de sessão
- Atribuição de fila de processamento
- Gerenciamento de tráfego
- Roteamento de solicitações
Núcleo do Agent Runner
O agent runner é o coração do sistema onde ocorre a montagem do prompt. Ele seleciona o modelo de IA apropriado, adiciona histórico de conversas e usa um gerenciador de janela de contexto para manter os dados dentro dos limites de tokens.
- Seleção do modelo de IA
- Montagem dinâmica de prompts
- Rastreamento do histórico de conversas
- Gerenciamento da janela de contexto
Chamada de API LLM e Ciclo do Agente
O agente entra em um ciclo iterativo onde se comunica com o LLM. Ele processa respostas e decide se executa uma ferramenta ou fornece o texto final, garantindo que as ações sejam baseadas em resultados em tempo real.
- Chamadas de interface do modelo
- Processamento de resposta
- Lógica de execução de ferramenta
- Ciclo de raciocínio iterativo
Caminho de Resposta e Saída
Uma vez que o agente completa seu raciocínio, o caminho de resposta gerencia a entrega. A saída é transmitida de volta através do adaptador de canal, garantindo que o usuário receba o texto final instantaneamente na plataforma de chat escolhida.
- Saída em streaming
- Geração de texto final
- Formatação específica para o canal
- Feedback do usuário em tempo real
Perguntas frequentes sobre este modelo
-
Qual é o papel principal do Gateway Server nesta arquitetura?
O Gateway Server atua como o controlador de tráfego para toda a arquitetura. Ele realiza a identificação de sessão para acompanhar usuários individuais e suas interações específicas. Além disso, ele atribui solicitações a filas de processamento para equilibrar a carga do sistema. Isso garante que os agentes de IA lidem com várias solicitações sem problemas, sem travar o servidor ou perder dados importantes.
-
Como o Agent Runner gerencia o contexto da conversa?
O Agent Runner funciona como uma linha de montagem para a inteligência da IA. Ele seleciona o modelo de IA apropriado e constrói dinamicamente prompts do sistema, mesclando histórico e instruções. Além disso, o Context Window Manager evita o transbordamento de dados monitorando contagens de tokens e acionando resumos quando necessário. Isso garante que o agente permaneça focado e coerente durante conversas longas sem perder detalhes importantes do usuário.
-
O que acontece durante o processo de Agent Loop?
O Agent Loop é um processo iterativo onde a IA decide como responder. Se o LLM identifica uma tarefa que requer dados externos, ele aciona uma chamada de ferramenta para execução. Uma vez que a ferramenta fornece um resultado, o loop reinicia para processar a nova informação. Este ciclo se repete até que o modelo gere o texto final, garantindo que cada resposta esteja fundamentada em ações do mundo real.